Le Cluster Health Monitor d’Oracle, ou CHM, est un outil de monitoring et de diagnostic indispensable pour analyser certaines anomalies sur les nœuds d’un cluster Oracle (performance CPU, mémoire, réseau, process). Les données collectées par le CHM sont stockées dans une base de données dédiée, appelée MGMTDB. Fournie en standard, la base de données MGMTDB est en quelque sorte l’AWR du cluster, et officie en tant que repository de ses métriques.
Dans la version 11g d’Oracle, ces données étaient stockées dans une base de données berkleydb (en un seul fichier). Ces fichiers pouvaient d’ailleurs finir par occuper beaucoup d’espace disque et saturer le FS. Depuis la version 12c, c’est une base Oracle de type MGMTDB qui a pris le relais. Un avantage ? Certainement, mais qui comporte là encore quelques inconvénients. Par exemple, si les process MGMTDB viennent à se multiplier, alors ils peuvent rapidement saturer les CPU et ralentir tous les traitements sur les bases du cluster. Que faire alors ? On oublie, ou on optimise ?
Un système souvent décrié malgré son intérêt
Pourtant particulièrement utile, le MGMTDB souffre d’une image souvent défavorable chez les administrateurs de base de données. Au nombre des accusations les plus fréquentes dans sa mise en examen :
Ça prend de la place sur le disque !
- Oui, mais on peut régler la rétention. Relaxé !
Ça ne sert à rien ! On peut la supprimer ?
- C’est parce qu’on ne sait pas l’utiliser correctement. Relaxé !
C’est buggé ! (Saturation des CPU, rétention non respectée, etc.)
- Oui, mais c’est moins vrai maintenant. Et il est possible de mettre en place des workarrounds (relocalisation, purge manuelle) pour améliorer le process. Relaxé !
Quelques commandes bien utiles
Gestion de la ressource (1) $GRID_HOME/bin/crsctl start|status|stop res ora.crf -init # ressource ohasd
Exemples d’utilisation (1)
Cas de nouveaux devices (disks) non détectés ? stop puis start
Fichier bdd trop gros (11.2) : stop, purge fichier , start
Gestion de la ressource (2) $GRID_HOME/bin/srvctl relocate mgmtdb [-node node_name]
Exemples d’utilisation (2)
Process de l’instance MGMTDB prennent tous les CPU sur un nœud : relocate de l’instance
Sur quel noeud est le master ? oclumon manage -get master
Où sont les logs ? répertoires $CRS_HOME/log/$HOSTNAME/crf*
Comment améliorer la configuration du CHM ?
L’une des premières actions à effectuer est de vérifier la rétention actuelle et si elle correspond bien à l’utilisation que l’on veut en faire : c’est là que la commande oclumon entre en scène !
Puis dans le cas où le repository ne serait pas assez grand, il convient de le redimensionner pour en augmenter la durée de rétention. Comme l’utilité est d’investiguer a posteriori des incidents, il est souhaitable de garder au moins 2 voire 3 jours d’historique (afin de récupérer les données du samedi et du dimanche pour une analyse le lundi matin par exemple).
Affichage de la rétention actuelle
[grid@node] $ oclumon manage -get repsize CHM Repository Size = 136320 seconds
Affichage de la taille proposée pour la rétention cible
[grid@node] $ oclumon manage -repos checkretentiontime 200000 The Cluster Health Monitor repository is too small for the desired retention. Please first resize the repository to 3006 MB
Changement de la retention
[grid@node]$ oclumon manage -repos changerepossize 3006 # MB The Cluster Health Monitor repository was successfully resized. The new retention is 200000 seconds.
Présentation du démon « logger »
Cluster Logger Service (Ologgerd)
Process “Maitre” qui reçoit des données des autres nœuds et qui les enregistre dans la base MGMTDB. Un process par cluster.
[grid@node#1] ~ $ oclumon manage -get MASTER Master = node#2 [grid@node#1] ~ $ oclumon manage -get alllogger -details Logger = node#1 Nodes = node#1, node#2
Présentation du démon « system monitor »
System Monitor Service (Sysmond)
Un process Sysmond par nœud qui collecte les données (CPU, mémoire, disque…) du nœud local et les envoie au Cluster Logger Service centralisé
[grid@node#2] ~ $ oclumon manage -get mylogger Logger = node#2
Pour en savoir plus : extraire les informations de la base MGMTDB
Commande d’extraction (12.2) :
oclumon dumpnodeview [-allnodes | -n node1 ...] [-last duration | -s timestamp -e timestamp] [-i interval] [-v | [-system][-process][-procag][-device][-filesystem][-nic][-protoerr][-cpu][-topconsumer]] [-format format type] [-dir directory [-append]]
A noter :
- Timestamp au format YYYY-MM-DD HH24:MM:SS
- collection interval : en intervalles de 5 secondes.
- format type : legacy, tabular, or csv (permet de retraiter les informations)
ATTENTION : L’intervalle de collecte est de 5 secondes, pensez donc à limiter l’intervalle start / end !
Et si la commande génère une erreur :
Erreur: ORA-12537: TNS:connection closed (cas 19c)
Le fix (en tant que user grid)
srvctl stop mgmtdb srvctl start mgmtdb srvctl status mgmtdb – Database is enabled – Instance -MGMTDB is running on node xxxxxxx Puis sur le node xxxxxx (en tant que grid) mgmtca configRepos setpasswd -allusers
Le CHM se met à table et nous livre ses infos (classées par catégorie)
CPU : ID, system[%], user[%] , nice[%] , usage[%] , iowait[%] , steal[%] (1)
(1) le Steal time ou « temps de vol CPU » est le pourcentage de temps pendant lequel un processeur virtuel attend un vrai processeur pendant que l’hyperviseur dessert un autre processeur virtuel
DISK : diskname,ior[KB/s],iow[KB/s],ios[#/s],#qlen,wait[msec],svctm[msec],util[%],type,
complétable (1) avec AsmDevice=f(diskname) , FailureGroup=f(diskname), DiskGroup=f(diskname)
(1) à enrichir manuellement ou via un script
Filesystem : nom, type, total[KB],used[KB],available[KB],used[%],ifree[%]
NIC (carte réseau) : id/name,pktsin[#/s], outdiscarded[#/s], netrr[KB/s], pktsout[#/s], iunicast[#/s], netwr[KB/s], errsin[#/] ,innonunicast[#/s], neteff[KB/s], errsout[#/s], type,nicerrors[#/s], indiscarded[#/s], latency[msec],mtu[B]
PROCESS nom, class, state, nice, priority, #threads, iops[#/s], ior[KB/s], iow[KB/s]ior[KB/s], #fdsvmem[KB], shmem[KB], privatemem[KB],cumulative_cpu,cpuusage[%], #procf,dlimit,ppid,Pid (1)
(1) quand le process indique une session Oracle (oracle${ORACLE_SID}) on n’a que le PID, mais pas la session au sens Oracle …. dommage !
SYSTEM #pcpus, shmem[KB],swpin[KB/s], #nfs, #cores, buffercache[KB],swpout[KB/s], loadavg1,#vcpus, bufferKB], pgin[#/s], loadavg, cpuht,cache[KB], pgout[#/s], loadavg, osname, pagecache[KB], netrr[KB/s], nicErors[#/s], chipname,s labreclaim[KB], netwr[KB/s], #intr,cpuusage[%], memavl[KB],#procs, #ctxswtch,cpusys[%], swapfree[KB], #procsoncpu,cpuuser[%], swaptotal[KB], #procs_blocked,c punice[%], hugepgetotal[KB], #rtprocs,cpuiowait[%], hugepagefree[KB], #rtprocsoncpu,cpusteal[%], hugepagesize[KB],#fds,#cpuq,ior[KB/s], #sysfdlimit,physmemfree[KB],iow[KB/s], #disks, physmemtotal[KB], ios[#/s], #nics,
TOPCONSUMMERS : topcpu[%],topprivmem[KB],topshmem[KB],topvmem[KB],#topfd,#topthread,
topio[KB/s]
Comment analyser les données obtenues ?
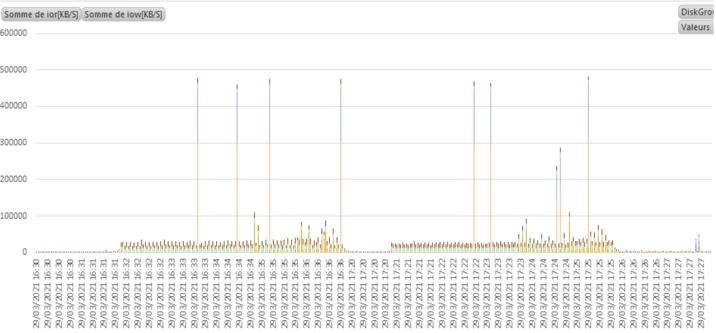
Pour commercer, extraire les données en CSV avec la commande oclumon dumpnodeview, pour tous les nœuds, mais avec un intervalle de temps (très) limité.
Charger les données dans Excel et enrichir les colonnes (DiskGroup,…)
Créer un graphique croisé dynamique afin de mieux visualiser les data.
Pensez à garder ce fichier en cas de besoin ultérieur !
Les démons n’ont pas parlé ? Cherchons d’autres indices !
Un suspect laisse toujours des traces, y compris lors d’une éviction de nœud RAC !
cd $ORACLE_HOME/crf/db/node#1 ls –alrt … -rw-r--r-- 1 root root 12339642 Apr 19 16:58 eviction_dump_19-APR-2021-16:58:55.txt -rw-r--r-- 1 root root 12304831 Apr 19 16:58 eviction_dump_19-APR-2021-16:58:58.txt -rw-r--r-- 1 root root 12273410 Apr 19 16:59 eviction_dump_19-APR-2021-16:59:13.txt -rw-r--r-- 1 root root 12198274 Apr 19 16:59 eviction_dump_19-APR-2021-16:59:18.txt
Fichiers txt à retraiter pour comprendre la cause…
Acquitté ou condamné ?
Au final, malgré quelques inconvénients qui se règlent assez facilement grâce aux commandes de base, l’intérêt des infos fournies sur le système, le stockage, le réseau justifient pleinement l’utilisation du Cluster Health Monitor par le DBA Oracle !